Huffmanovy kódy: příklady, aplikace
V tuto chvíli málo lidí o tom uvažuje,jak komprese funguje. Ve srovnání s minulostí je používání osobního počítače mnohem jednodušší. A prakticky každá osoba pracující s souborovým systémem používá archivy. Ale jen málo lidí si myslí, jak fungují a jaký je princip komprese souborů. První verze tohoto procesu byly Huffmanovy kódy a stále se používají v různých populárních archivorech. Mnozí uživatelé si ani nemyslí, jak snadné je komprimovat soubor a podle toho, jak funguje. V tomto článku se podíváme na to, jak se komprese provádí, jaké nuance pomáhají urychlit a zjednodušit proces kódování a zjistíme, jaký je princip konstrukce kódujícího stromu.
Historie algoritmu
První algoritmus pro efektivníkódování elektronických informací byl kód navržený Huffmanem v polovině dvacátého století, jmenovitě v roce 1952. V současné době je hlavním základním prvkem většiny programů vytvořených pro kompresi informací. V současnosti je jedním z nejpopulárnějších zdrojů tohoto kódu ZIP, ARJ, RAR archivy a mnoho dalších.
Princip účinného kódování
Základem Huffmanova algoritmu je schéma,Umožňuje nahradit nejpravděpodobnější, nejčastěji se vyskytující symboly s kódy binárního systému. A ty, které jsou méně časté, jsou nahrazeny delšími kódy. Přechod na dlouhé kódy Huffmanu nastane až poté, co systém použije všechny minimální hodnoty. Tato technika umožňuje minimalizovat délku kódu pro každý znak původní zprávy jako celku.

Huffmanův kód, příklad
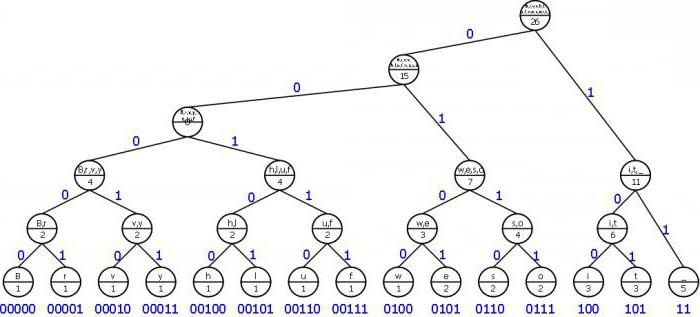
Pro ilustraci algoritmu, dejte nám tografická verze konstrukce stromu kódů. Chcete-li použít tuto metodu, je užitečné objasnit definici některých hodnot nezbytných pro koncept této metody. Sada oblouků a uzlů, které jsou směrovány z uzlu do uzlu, se obvykle nazývá graf. Samotný strom je graf se souborem určitých vlastností:
- v každém uzlu nelze zadat více než jeden oblouk;
- jeden z uzlů musí být kořen stromu, tj. žádný oblouk by ho vůbec neměl zadat;
- pokud se z kořenu začne pohybovat podél oblouků, měl by tento proces umožnit dostat se úplně do libovolného uzlu.

Algoritmus pro stavbu stromu podle Huffmana
Konstrukce Huffmanova kódu je z písmenvstupní abecedy. Zobrazí se seznam těchto uzlů, které jsou v budoucím stromu kódu zdarma. Hmotnost každého uzlu v tomto seznamu by měla být stejná jako pravděpodobnost výskytu písmena zprávy odpovídající tomuto uzlu. V tomto případě je mezi několika málo volnými uzly budoucího stromu vybrána ta, která váží nejméně. Současně, pokud jsou pozorovány minimální indikátory v několika uzlech, je možné libovolně vybrat libovolnou dvojici.
Zlepšení efektivity komprese
Pro zvýšení účinnosti komprese je nutnéčas na vytvoření stromového kódu, který používá všechna data týkající se pravděpodobnosti písmen, které se objevují v konkrétním souboru připojeném ke stromu, a neumožňují jejich rozptýlení nad velký počet textových dokumentů. Pokud poprvé procházíte tímto souborem, můžete okamžitě vypočítat statistiky o tom, jak často se vyskytují písmena z objektu, který má být komprimován.
Zrychlení procesu komprese
Pro urychlení algoritmu definice písmenJe třeba provádět ne na ukazatele pravděpodobnosti výskytu tohoto nebo tohoto dopisu a na četnosti jeho výskytu. Díky tomu se algoritmus stává jednodušším a práce s ním je značně zrychlena. To také zamezuje operacím spojeným s plovoucí čárkami a dělením.
Závěr
Huffmanovy kódy - jednoduché a dlouhotrvajícíalgoritmus, který je stále používán mnoha známými programy a firmami. Jeho jednoduchost a přehlednost umožňují dosáhnout efektivních výsledků komprese pro soubory libovolné velikosti a významně snížit prostor, který obsazují na úložném disku. Jinými slovy, Huffmanův algoritmus je dlouhý studovaný a dobře navržený schéma, jehož význam se až dodnes nezmenšuje.









